Failover
XplicitTrust supports transparent failover for services hosted on an Asset by pairing the primary Asset with a Virtual Asset that shares the same DNS name.
When the primary Asset becomes unreachable, clients automatically fall over to the gateway asset that provides the Virtual Asset, without any user intervention and without DNS changes.
How it works
The key requirement is that the primary Asset and the Virtual Asset are configured with the same DNS name.
- The primary Asset runs the XTNA-agent and serves the service directly.
- A second Asset — the gateway asset — is configured with a Virtual Asset that points to the same service (for example, by its local IP on a secondary network path, or to a standby host).
- Both the primary Asset and the Virtual Asset are assigned the same DNS Name in the Admin Console.
- When a client resolves the shared DNS name, it receives endpoints for both the primary and the virtual path. Connections are attempted against the most recently working endpoint first; if it fails, the client transparently rotates to the next one.
Because failover happens inside the agent's connection layer, existing sessions re-establish against the gateway path without requiring a DNS TTL to expire.
Single gateway failover
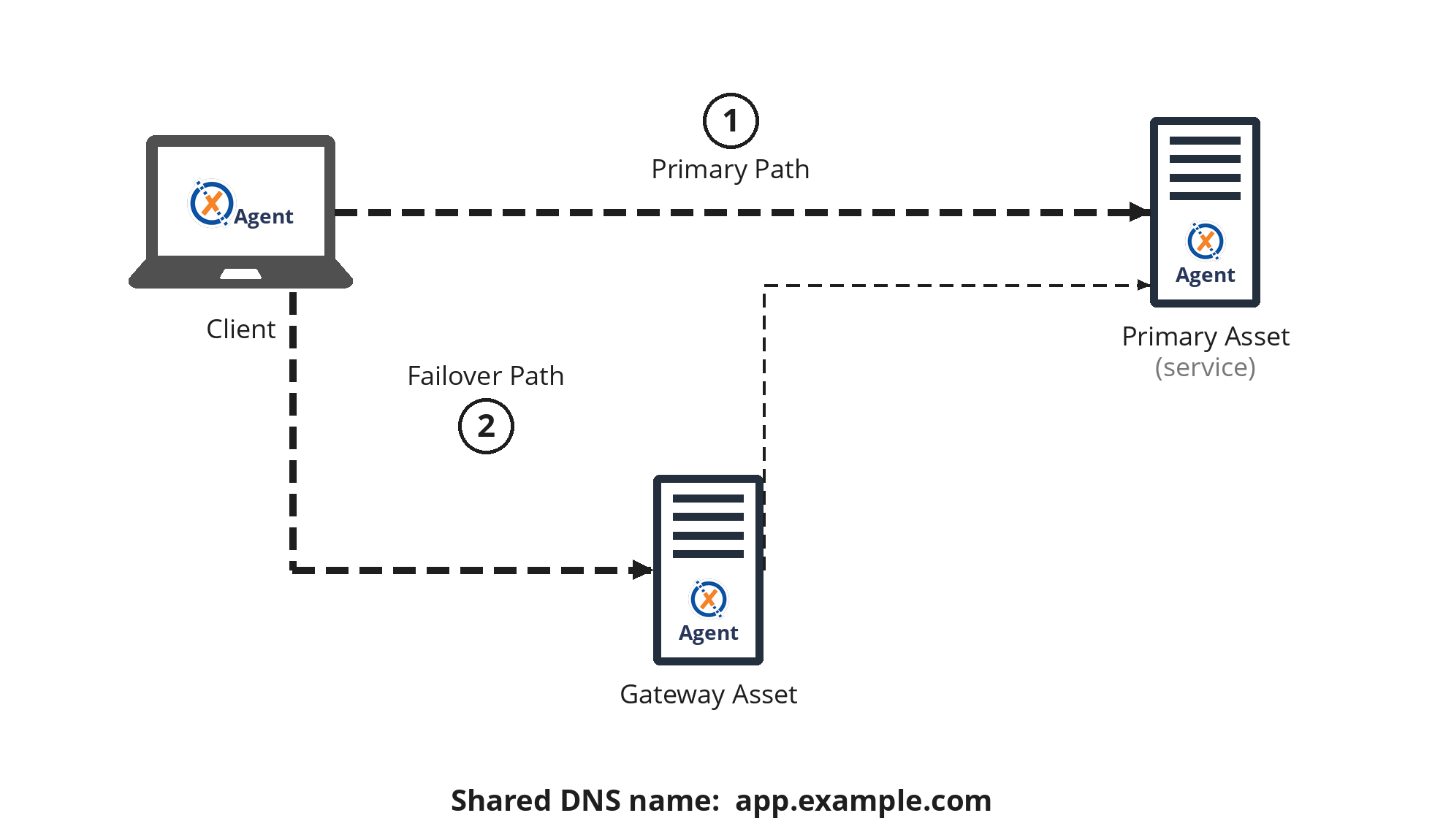
The simplest form of the pattern: one primary Asset and one gateway Asset both covering the same service.
What this protects against
Failover operates at the agent / reachability layer, not at the service layer. It keeps the service reachable when the primary Asset's agent path breaks while the service itself is still running, for example:
- The XTNA-agent on the primary host crashes, is stopped, or hits a software/certificate issue.
- The primary host loses its WAN link and the agent can no longer reach the XT infrastructure, even though it's still reachable on the LAN.
In these cases the service process itself is still running — it just isn't reachable via the primary agent anymore. The gateway Asset sits on the same LAN as the service and talks to it over its local IP, so clients still get through.
It does not protect against anything that takes the service itself down: a crash of the service, the service host rebooting or going offline, or a LAN outage between the gateway and the service. If you also need to cover service-host failure, point the Virtual Asset at a standby host running the same service instead of the primary host's local IP — the gateway will then route failover traffic to the standby, which keeps serving while the primary host is down.
Topology
- Primary Asset —
app.internal— an XTNA-agent running on the service host itself. - Gateway Asset — a Linux Asset on the same network segment as the service.
- Virtual Asset —
app.internal— configured on the gateway asset, with its Public IP set to the service's local IP (or the IP of a standby host, to also cover service-host failure).
Multiple gateway assets
The same underlying service can be made reachable through more than one gateway asset by configuring a separate Virtual Asset on each gateway, all sharing the same DNS name.
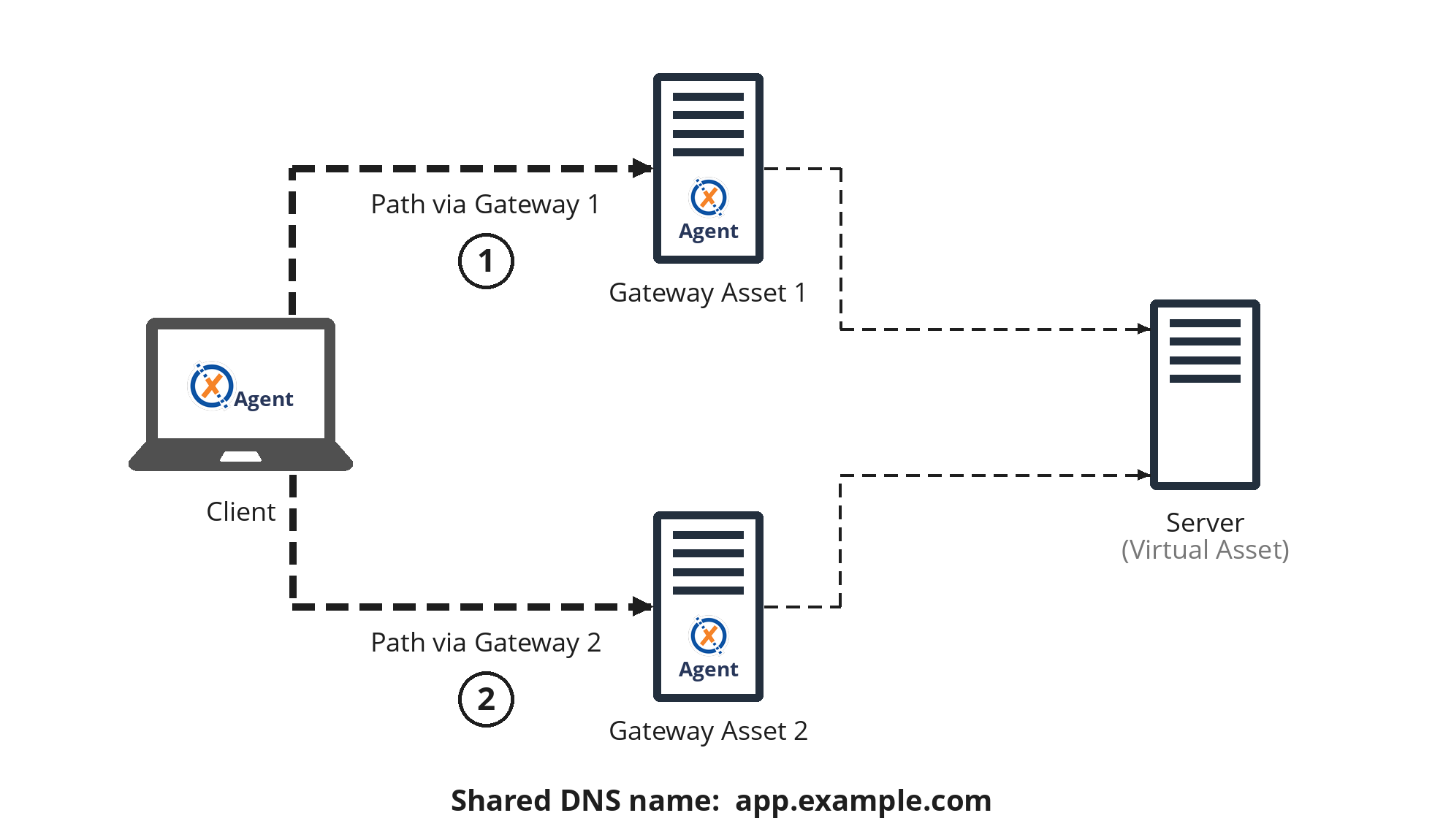
Each gateway adds another candidate path for the shared DNS name. Clients will rotate through all available paths on failure, so a setup with two gateway assets gives you two independent paths to the same service.
This is useful when the gateway assets themselves sit on different network segments or in different sites, so that a single gateway outage doesn't take down the failover path.
The same principle applies when the service is exposed through a Subnet or Managed Subnet on each gateway instead of a Virtual Asset — as long as the service resolves to the same DNS name across all paths, clients will rotate between them the same way.
Policies
The primary Asset and the Virtual Asset are two separate destinations from the perspective of policies, even though they share a DNS name. The shared DNS name enables the agent-side failover at the connection layer — it is not a policy-level alias.
For failover to work, every policy that grants access to the primary Asset must also grant access to the Virtual Asset (and vice versa). If only one endpoint is covered by a policy for a given client, that client will only ever see one candidate address for the shared DNS name and there will be nothing to fall over to.
The simplest approach is to add both the primary Asset and the Virtual Asset as destinations on the same policy.
Notes
- The primary Asset and the Virtual Asset must share every DNS name on which failover should apply.
- The gateway asset must be able to reach the service's IP directly (usually same LAN).
- Failover is bidirectional in the sense that either endpoint may serve traffic at any given time; clients always prefer whichever path most recently worked.